話說最近正在讀《無瑕的程式碼》這本書,所以一直擺在手邊,三不五十就會瞄這本經典鉅作一下,不過最近眼花常會看錯書名...
當程式寫出來,功能完整,沒啥bug,自我感覺天下無敵的那一瞬間,就會看成「無敵」的程式碼
當不小心打開Open Source的專案原始碼時,一堆看不懂的程式碼在眼前,老鼠怎麼捲都捲不完,眼花撩亂的那一瞬間,就會看成「無窮」的程式碼
當看到某些函式訂了參數,傳進去卻沒用到,咒罵這分明是脫褲子放屁的那一瞬間,就會看成「無用」的程式碼
當看到某些大師的程式碼,想說來重構一下,以證明自己比大師更厲害,卻發覺完全沒地方下手,體會到大師果然厲害的那瞬間,就會看成「無缺」的程式碼
當看到某些程式碼模組交互呼叫,糾纏不清,你濃我濃時,想修個bug卻不知從何下手時,就會看成「無縫」的程式碼
當看到某些程式碼根本只是隨便寫寫,完全不考慮後續維護,魔術數字四散各地,變數名稱與流程邏輯完全對不上,改起來簡直想要跳樓,就會看成「無恥」的程式碼
當bug截止時間將到,知道錯誤在這段,卻完全沒有idea要怎麼改,就會看成「無望」的程式碼
當一直寫一樣的東西,絲毫沒有變化,感覺悶的要死時,就會看成「無趣」的程式碼
當看到某些程式碼內含一堆架構,實際上架構根本就沒做到什麼重要的事,完全是一個熱臉貼冷屁股的那一瞬間,就會看成「無感」的程式碼。
當程式碼架構設計的好,還貼心的附上完整的測試案例,要新增功能,要修bug都是一塊蛋糕,照著架構改好跑跑測試就搞定,感覺人生輕鬆愉快的那一瞬間,就會看成「無痛」的程式碼。
當看到好不容易重構後變得比較簡單的程式碼,一次又一次被加個阿紗布魯,天邊飛來的一朵邏輯的那一瞬間,就會看成「無力」的程式碼
當花了十年參透大師寫的那一行程式碼背後所隱含的大宇宙的奧秘的那一瞬間,就會看成「無極」的程式碼。
軟體進步到現在,開發測試部署全部都可以用程式碼控制,四輪傳動系統、行車主動安全系統,物聯網,OOXX什麼東西都會有程式碼存在,當我想到2XXX年還是有一堆人要寫程式碼的那一瞬間,就會看成「無限」的程式碼。
以上純屬嘴砲,我只是想表達這本書的中文標題,真的意義深遠...
2014年11月9日 星期日
2014年10月8日 星期三
我的BDD物語1
我的BDD物語1
從開始使用TDD之後一年多,發覺不管是解Bug還是做Enhancement,沒有寫Test就會覺得全身不對勁,在這段期間,也看到了許多TDD進階到BDD的分享文章,像是INTRODUCING BDD,最有感的應該是這篇WHAT’S IN A STORY?,看了之後發覺原來寫User Story是很簡單的,有固定的格式,也可以很好的描述出系統的行為。之前看到那種厚重的文件裡面內含的Use Cases,我心想,到底這種文件誰會來維護,一定不是Developer...,不是Develper維護的結果就是文件跟不上code,基本上這種文件都要準備的很完整的形式,是給某些走重裝軟體流程的團隊,而我們寫code的時間都不夠了,哪有時間在那邊改一堆奇奇怪怪的Word、Excel、PDF。而以BDD的方式來作,只要寫出如下的Story:就可以就寫Behavior Test,文件格式也很簡單,用普通文字檔就可以,也可以用Markdown之類的格式來呈現,在有需要與Product Owner或Feature Owner討論的時候就可以派的上用場,討論完馬上就可修改,寫Behavior Test時一想到其他Case也可以修改。
故事是這麼開始的
有了TDD的經驗與BDD的知識之後,我在開發N功能時就實際應用上去,N功能對我而言是有點莫名其妙的功能,感覺與我們系統的設計背道而馳,這部份我就不多說,總之,開了一次又一次的會,大概對實際需求有個譜,在還沒有開始寫Code之前,我就先寫出了一個又一個的User Story,其實撰寫User Story也沒辦法花太多時間,一開始大概一兩個下午斷斷續續就完成初版,由於系統裡還有很多面向,例如備份、升級、組態模板、事件、還有各式各樣的使用者行為,有些面向我也沒有實際接觸過,所以只能寫出User Story的Title。接下來開始寫Code之後,我的方式是每個User Story對應一個Class,每個Scenario對應一個Test Method,每個Scenario都代表User的一個行為,當然也有系統因為狀態變化的行為。以TDD的方式來做,當然就是先把Test寫好,然後再去修改Production code裡面的內容,來滿足Test的結果。這個作法的好處在開發時我體會到幾項:
- 一邊寫會一邊思考除了目前寫的Scenario之外,還有哪種不同的Scenario,如果想到新的,就在文件上加一個Scenario。接下來繼續做,這樣的好處是比較不會漏掉。
- 另外就是成為自己的程式碼的第一個使用者,基本上Test在做的事情,就是User透過Web UI或是CLI過來做的事情,如果沒有提供清晰的界面,方便不容易錯的參數,第一個遭殃的就是寫Test的自己。
- 減少把整個系統跑起來測試的時間,我們家的系統大到爆,基本上是沒有辦法在本機把系統所有元件跑起來,通常我沒寫Test的測法都是把jar丟到遠端機器上執行,然後操作UI看log。這樣子超沒有效率,以我們寫Backend的人來說,其實User的行為最後都是做資料的操作與運算,只要能夠用Test確保資料操作與運算都正確,到最後階段再測試與UI的整合就可以。
- 相較於以往都是對一般功能性的Class寫Test,有可能是要測試Class的某些運算邏輯,或是某些Business Process,對於不懂的人,或是過了一年半載再來看的人,簡直就是一頭霧水,用BDD來寫Test可以很容易看懂到底要跑哪一種使用者行為,而且這些使用者行為是不管內部程式架構怎麼改,都必須一直有效,除非產品本身的功能有所變化。 雖然開發初期就有體會到BDD的好處,不過為了要讓code可以看起來BDD一點,花了不少時間在對我們底層架構東摸摸西摸摸,還好前輩們寫了不少Test範例,很多一開始不知道如何使用的Entity,看了相關的Test寫法之後,也可以依樣畫葫藘,只可惜沒辦法用我們自家新一代的Test專用資源管理系統,光是花在資源管理的問題,我就不知道多花了幾個小時...要寫Test,把好用的Framework準備好也是很重要的呀!
從A Branch整合到B branch
我一直都在A branch開發,明明就是做同一版本的東西,一開始又分成Dev branch與Release branch,這我是沒啥意見,但是兩個branch之間沒有sync則是用Peforce的大忌!最後A branch要廢掉,要把所有開發的成果全部Integrate到B branch上,branch owner的策略就是讓Developer自行一個一個Change list(Change list是Perforce修改的單位),這個策略本質上就是把所有的複雜度交給Developer,然後再來讓QA開一堆bug來追Developer。我個人是不太喜歡啦,既然要用Perforce就應該套用Perforce的best practice才對。遇到這種狀況,我當然就是把所有在A branch的Change list全部Merge到B branch上,然後跑Test,全過!就...收工。4X的Scenario的Test都過了,有問題就交給QA發現吧,這次整合大概花費時間是一個下午不到。我的code被蓋掉了!
由於我很快的就從A branch到B branch整合完畢,接下來就是其他人整合自己開發的成果到B branch,某天下午,天色已近黃昏,我突然發現,我這個功能的Test在Jenkins上跑的自動測試失敗了!點進去Jenkins的頁面一看,這些Test我之前跑過都是OK的呀,看到失敗的Test,因為是BDD,就等同是使用者操作一樣的動作會失敗,大概有快一半!這下包了,難道是我無意識做了什麼要命的動作,馬上打開IDE看一下Source code,結果發現...我寫的code怎麼變成之前的模樣!結果用Peforce找出了真兇,原來是我們遠在印度的同事,把code從A branch整合到B branch時把我的code覆蓋掉了...接下當然又是一堆信件風暴來來回回,最後,只好請那位同事Backout他的整合成果,我只能說,還好我有Test,不然過了幾天Release給QA之後才發現就...什麼!要改ID!
這個N功能進了QA測試階段之後,主要流程幾乎沒什麼問題,當然也是有些字串顯示,或是沒有考慮到流程,這種狀況當然是會在User story與Scenario上多加幾筆,也寫對應的Test,最後的Scenario Test數量來到61個,老實說,Test的程式碼數量是比實際功能數量來得多,一方面是我們的Test Framework還沒做到很簡潔,另一方面就是一個User Story再配合系統當下的狀態,本來就會有各種Scenario,code的數量較多也是理所當然。結果在QA測到了最後,這個N功能有一個User Story的Scenario我們沒有考慮到,結果Feature Owner不太能接受,我當下還真的有點難受,我做對了95%以上的Scenario,但是這個並沒有做對,我想,我有一件最重要的事情沒有做到位:BDD裡面的驗收測試案例,是Poduct Owner、Developer、QA共同決定認可的。
還記得我前文並沒有提到我有將寫出來的Scenario一一的與Feature Owner確認。以我們部門的架構、座位的遠近,同事之間的合作程度,我完全有機會與Feature Owner做確認,不過我卻沒做到。或許做了還是會疏忽掉這個Scenario,但是沒做到這點就是不夠專業...
經過一番討論之後,後來得出了個把底層資料結構所用的ID換掉來解決這個問題,啥,換ID!每個地方做運算與比較都用到ID耶!看起來好像要花不少時間,但我其實並不太抗拒,因為我們有BDD裡面的驗收測試案例,就算要改的地方比較多,但是只要最好能跑過這61個Test就應該沒太大問題。結果最後以不修改告一段落...
再來一次,從B branch到C branch
同樣的歷史果然又上演一次,聽說在這之後的Branch Model向Perforce的Best Practice看齊~這次我們再忍耐一下吧,懷著這樣的希望,我再次的把B branch的Change list整合到C branch,C branch是新版本的產品,架構有不少變化,整合過去,原本N功能的Scenario Test也有一半以上有問題,不過大概花了一個上午的時間就...搞定了。看到61個Test全亮綠燈,心中有股事情就該是這樣的確定感...結語
這次使用BDD做Feature的開發,還真的學到蠻多的,好處與難處全都遇到了,對我自己而言,好處遠遠大於難處。另外- 與Product Owner(Feature Owner)確認BDD裡面的驗收測試案例
- 簡化Test的撰寫方式,讓驗收測試可以用更有表達性的方式呈現
2014年4月18日 星期五
筆記:RESTful API
最近有機會看RESTful API的設計,雖然自己沒有參與,但是也把握機會看了一遍。首先先從Http協定說起,Http協定不只用在傳輸Web的內容上,也有很多Client應用程式與Server溝通都使用Http協定,例如手機App,遊戲,甚至一些雲端的服務都是透過Http協定來提供服務。但是Http只是協定,至於要以什麼順序傳,傳什麼東西,其實都是自由的,所以也造成沒章法隨便亂寫的狀況,而REST風格是一個業界公認,我們自己也可以理解接受的一種解決方案。遵照REST的風格,做出來的架構因為Server不需要記錄執行狀態,所以天生就有較好的擴展性,簡單說,只要後端資料庫夠強,就可以一直水平擴充Web Server,透括負載分配進來Web Server的請求,就可讓支援使用者數量上到百萬。這就是無狀態設計屌的地方。
其實我家老大找到的這篇,就已經完整說明設計RESTful API各種要注意的地方:
http://www.vinaysahni.com/best-practices-for-a-pragmatic-restful-api
http://www.vinaysahni.com/best-practices-for-a-pragmatic-restful-api
以下是個人簡單的筆記:
透過Http協定來提供服務有以下好處:
- Http協定已經是一個成熟穩定的傳輸協定,累積了業界的經驗,而且有許多的Http Server支援,不用自己再打造協定,只須選擇一種Http Server來使用,並把應用程式佈署進去。
- Client端也有許多現成的Open Source實作,不需自行打造穩定可靠的Client端
- 協定都是以文字為主,理解與除錯較簡單
- 至於傳輸內容部份,應用程式相關資料,目前業界都是使用肉眼可讀的JSON,怕字串容量過大,各家http server都有現成的工具可壓縮。
- 安全部份有https可以使用,加密也不需自行處理,可以使用Open Source的Solution
- Http本身也支援Cache機制,善加利用對於處理大量讀取需求也會很有幫助。
REST:Representational State Transfer,含狀態傳輸,來自Roy Fielding博士的論文
是一種軟體架構風格,在目前的Web Service實現方案中,與SOAP,XML-RPC簡單許多,這兩種我光是看就頭暈,所以REST已經變成實現Web Service的主流。科技走向始終來自於人性,一看就覺得違背工程師懶惰天性的規格,根本不需要花太多時間去看。
RESTful Web API,是使用HTTP並遵循REST原則的Web API,比較簡單的定義可以看 http://zh.wikipedia.org/wiki/REST ,
簡單易懂的RESTful CookBook:http://restcookbook.com/
可以看看GitHub怎麼訂的:https://developer.github.com/v3/
Google api explorer:https://developers.google.com/apis-explorer/#p/
Twitter的REST API:https://dev.twitter.com/docs/api/1.1
在把HTTP Method對應到Resource存取方式時:
GET-->讀取Resource
POST-->新增Resource,呼叫多次會新增多個
PATCH-->更新Resource,可作部份更新
PUT-->替換Resource,用新的Resource換掉一個舊的Resource
DELETE-->刪除Resource
另外有一個表格一定要了解:from http://restcookbook.com/
| HTTP Method | Idempotent | Safe |
|---|---|---|
| OPTIONS | yes | yes |
| GET | yes | yes |
| HEAD | yes | yes |
| PUT | yes | no |
| POST | no | no |
| DELETE | yes | no |
| PATCH | no | no |
Idempotent:代表Http Request會改變Server資料內容,但多次Request結果都不會改變。
Safe:代表Http Request不會改變Server資料內容
在設計RESTful API時,處理什麼資源要對應什麼Method,要小心考慮是否需要Idempotent與Safe。例如想更新某筆已經存在的使用者資料,卻用POST就瞎了。雖然還是可以作,但最好不要宣稱是RESTful。
以下是一些設計上的小筆記:
版本直接寫在URI上
只要有API就會有版本問題,早期版本資訊是放在http的request body裡面,但是這樣可讀性並不好,而且這個Request是哪個版本的,要解析Request body才知道。現在比較有彈性的設計是放在URL上,例如:
/v1/team/:id/members
/v1/team/:id/members/:user
到
/v3/team/:id/members
/v3/team/:id/members/:user
當Server升到v3的時候,如果實作相同,可以把v1的Request導到v3,達成Backward Compatible,如果實作不同,就保留v1的實作。
Enable與Disable的設計
要Enable/Disable某項資源時,可以做成HTTP PUT與HTTP DELETE,以下是Github在Repository加Star的例子:
- PUT /user/starred/:owner/:repo:對某個repository加Star
- DELETE /user/starred/:owner/:repo:對某個repository去掉Star
API就是User Story
在定義API時,用User Story來表示API比起用資料存取來表示API更好,因為這樣User Story就浮現,也不會多開放不需要的東西出去。以下是Github對於管理Team的API列表:
- List teams
- Get team
- Create team
- Edit team
- Delete team
- List team members
- Get team member
- Add team member
- Remove team member
- List team repos
- Check if a team manages a repository
- Add team repository
- Remove team repository
- List user teams
可以看到紅色的項目是特殊條件查詢,這樣把一個一個User Story列出來,開發的方式就會從資料導向變成使用者導向,我們只開放使用者需要的功能,寫出User Story就代表我們充分研究過使用者需求,寫出User Story還可進一步作BDD與ATDD,這可是一個軟體工程層次的進化!
以Aggregate為單位操作
Aggregate(你也可以叫做Entity,我在這裡是用DDD的講法)概念的使用,早期Http PATCH不風行,每次要更新資料,都要把完整一包資料準備好,一併Http PUT上去,較耗時間與計算資源,所以一種變通的作法,就是細分出很多URL,來對一個Aggregate作paritial update,例如有一個team Object,JSON如下:
{
"url": "https://api.github.com/teams/1",
"name": "Owners",
"id": 1,
"permission": "admin",
"members_count": 3,
"repos_count": 10,
"organization": {
"login": "github",
"id": 1,
"url": "https://api.github.com/orgs/github",
"avatar_url": "https://github.com/images/error/octocat_happy.gif"
}
}
假設orgnization又臭又長,有1000 char,每次我要更新team的members_count我必需
PUT /teams/:id
這樣每次要傳那個orgnization,消費太大又沒意義,所以可以用
PUT /teams/:id/members_count
這類的URL,只需要傳members_count。
以上作法沒什麼錯,但是這樣URI會增加很多,而且team是一個邏輯上完整的Aggregate,而members_count離開了team,就什麼也不是。以架構的角度來看,API每次給出來的,都應該是完整的資料。唯一需要部份資料更新的情境,應該就是Web UI想要減少傳輸量所以要做partial update,至於partial get,只會讓API提供者與API使用者搞死自己。
現在有Http PATCH有支援partial update,所以更新資料可以用以下形式:
{
"url": "https://api.github.com/teams/1",
"name": "Owners",
"members_count": 3,
}
只要用PATCH /teams/:id就可以了
既然現在PATCH已經成為主流,那更應該保持API給出的資料是個完整的Aggregate,這樣可以讓簡化資料處理邏輯,也可減少URI的數量。
URI不一定要完整表示資料的階層
假設一個資料階層是:School包含Department包含Class包含Student
如果要拿某一個student,可能會設計成
/school/:schoolid/department/:departmentid/class/:classid/student/:studentid
這樣又臭又長的URI,這個作法把資料階層的複雜度直接呈現給使用者,如果用以下URI
/student/:studentid
是不是相對簡單,但是我們怎麼只根據studentid找到學生?這部份就是後台設計的問題,或許可以讓使用者指定schoolid與departmentid與classid在Request Body裡面,或許可以將studentid定義成整個應用程式都不會衝突的UUID,然後直接搜尋這個id,不管如何,設計URI的考量應該以想要怎麼實現User Story,而不是以內部資料階層來侷限User Story。
反過來說,如果User Story需要呈現Class與Student的關係,那也是可以定義成:
/class/:classid/student/:studentid
動詞放在URI的最後面
RESTful的標準用法都是以資源存取為主,但是有許多User Story不只使用資源,而是有一些動作要系統執行,那要用API來呈現呢?
- 把要執行的動作當作一種資源,然後去Patch,壞處是把動作當資源這種觀念上的轉換不太直覺,Ex: PATCH /comuters/:computerid/activated
- 把要執行的動作的目標資源,後面加上sub resource,然後作PUT/DELETE,等同上述的Enable/Disable,這其實也不太直覺,Ex: PUT /computers/:comuterid/active,DELETE /computers/:computerid/active
- 把要執行的動作放在URL的最後面,這個方式打破RESTful架構在URI只放名詞的規範,但是如果把動詞放在URI的最後面,且API從頭到尾保持一致,個人也覺得是最有說明性的方式。https://developers.google.com/prediction/docs/reference/v1.6/,在GET /project/trainedmodels/id/analyze 就是拿專案某id的訓練模型來做....analyze。
Parameter的使用方式
parameter是拿來放filter條件或是Sort條件,state=是filter條件,sort=是sort條件
GET /tickets?state=closed&sort=-updated_at
更複雜的運用就是放Search Criteria
總是使用SSL
使用SSL連線可以免去每個Request都要作認證授權的麻煩,最重要的是安全性!我們無法預期用戶會在什麼地方呼叫我們的API,最好最省時間的方式就是全部都用SSL連線!Https早就有這個基礎設施。雖然最近有個HeartBleed的案件,但是還是應該使用,真的中鏢再積極補救。
總是使用gzip
可以省掉60%的頻寬,而Twitter自己作的研究極端的Case可以省80%的頻寬,另外就是用gzip就不用擔心回傳格式排版,可以排成肉眼方便讀取的格式,也不會佔空間。
Error Code的定義
Http協定本身就已經定義了Error code以及其所代表的意義,規劃RESTful API時一般都是會按照Http協定的定義,來將應用程式的錯誤映射到Http Error Code:
4xx:代表Client傳來的資料有問題,可能是格式錯誤,欄位錯誤等。
5xx:代表Server內部處理時有問題,可能是連不到資料庫,程式處理錯誤等等,Client可以嘗試用同樣的Request再發一次。
把應用程式自己的錯誤碼映射到Http Error Code的理由是符合Client的預期,Client就算不看任何文件,光是看Http Error Code就可以知道是自己錯還是Server錯
至於Error code 500則是有不同意見,一種意見是如果Server有錯,不知道要發什麼就發500。一是完全不要發500,以免有人惡意攻擊。
2014年2月1日 星期六
筆記:Introducing Branch By Abstraction
接下來就看看Branch By Abstraction有多厲害,實際看下來,的確是一套很有用的方法,簡單來說,就是把整合的工分散到每日的開發中。但是要實行有一些現實的問題需要克服
- 當我要新加一個Feature,會改動3個Class,這3個Class可能所有Module都要參考,而且與其它Module的Code綁很緊,要抽成Abstraction要改動的地方也是會很多,根本就是翻了。
- 就算我做好抽象層,把所有Module參考到這三個Class的地方改為呼叫抽象層,這樣還是對Code有變動,也是有可能對產品造成衝擊。
- 如果這3個Class的修改連介面都換掉,整個Class改頭換面,煥然一新,原來的使用流程已經不在,就算有抽象層當緩衝,還是免不了對產品造成衝擊。
這些現實的問題,我想是可以克服的,第一就是要有完整的Test,Unit Test,Integration Test,UI Test,但是如果Test不夠完整,可以使用這招嗎?我想答案是肯定的,但是要邊做邊補Test。而沒有任何Feature Branch,大家都只看Trunk,也就是mainline,這件事對目前的我而言,簡直就是美麗的夢境!我自己參與的產品就有遇到這種狀況,目前是分支一個Branch來做,如果用Branch By Abstraction,新的東西就可以不用等好幾個版本之後才進mainline,也不用擔心如果合併回mainline,到底會是怎麼樣的地獄。如果我有機會參與決策,我一定直接就這麼搞。
另一點作者提到除了Release之外,完全沒有其它Branch,這點我還是有點存疑,除非有一套機制讓Developer拿著Commit去取得認證,保證不會Break掉任何東西。不然Developer自己一個人做測試還是有限,如何保證不Break mainline?如果一個產品的開發編制如下:
- 100個Developer
- 分成15個Team,有的Team人多,有的Team人少
- 25個Component,從Web UI,Mobile UI,Database,Domain,Infranstructure.....
- 有跨Component,跨Team修改的需求,也就是一個需求需要改UI,Domian,Infranstructure一路改到底。
所有人都進mainline,哇塞,這太硬了,如果有個超級CI Server Cluster,Developer把Commit送上去,5分內跑完所有Test,取得Commit Token,然後Commit,那我覺得OK。但是有這麼超級的CI Server嗎???如果沒有,感覺還是以Team為單位,有各自的Private Branch,一周或三天與mainline同步,然後各自有自己的CI,一周整合回mainline一次,把測試的負載分散到各個Team會比較好。Mainline當然也有自己的CI。不過這個方式對於跨Compoent與跨Team的需求,分出Private Branch也是可以,但是Branch要維護就麻煩...感覺跟在某一個Team的Branch會好些....
果然,分Branch就是麻煩的開始...
- "Branch by Abstraction"是很少人知道的Best practice
- 避免使用需要合併回mainline的Short lived feature branches
- 因為這些Branches的狀態隨著不斷開發,可能會無法正常運作,導致developer需要花很久的時間去整合,最後可能就是整合不完,不斷的再整合,這個short lived變成long lived...
但書
架構要滿足以下條件才能用Branch by Abstraction,這些條件與Agile Development相符合:
- 你已經將Application分成不同的Component
- 每一個Component在trunk裡面是一個目錄(有可能是階層式)
- 每一個目錄有它自己的Source,而且可以自己被build出來(有可能是階層式)
- 你有一組良好的unit tests而且這些tests可以展現components怎麼用
- CI可以管理大量的Component的建置,Maven-like Repository可以存放Build好的Compoent,只需透過下不同的Command就可以做好Branch相關Component的管理
- 你的管理方式對Release Planning有良好規畫
- 每個Developer有絕不能Break Build的Sense
你的Trunk可能會長的像這樣:
<root>
trunk/
foo-components/
foo-api/
foo-beans/
foo-impl/
build.xml
src/
java/
test/
cruisecontrol-config-snippet.xml
remote-foo/
bar-services/
bar/
build.xml
src/
java/
test/
cruisecontrol-config-snippet.xml
bar-web-service/
當你的團隊想要從Hibernate轉到iBatis,因為底層架構改變,所以架構師可能會建議要建立一個分支,否則trunk可能會Break數周,這時候Branch by Abstraction登場代替Branch by Source Control。
Hibernate:一套很有名的ORM
iBatis:也是一套ORM
Branch By Abstraction步驟
- 在要修改的地方導入一個抽象層,底層實作還是原來的實作,然後Commit
- 修改所有相關Class,使其呼叫這個抽象層,然後Commit
- 打造另一個抽象層的實作,撰寫對應的unit test,確定功能OK後Commit
- 步驟2相關Class參考的實作換成新的實作,抽象層不變,然後Commit
- 把原來的實作標為廢棄,或是直接砍掉(如果不想要轉移期)
- 刪除原來的實作,到這裡已經沒有需要原來的實作了
- 移除抽象層(如果抽象層寫的不漂亮)
簡單來說,就是這幾張圖:
來源:Martin Fowler的 http://martinfowler.com/bliki/BranchByAbstraction.html
一開始長這樣


抽出Abstraction Layer


其它Client呼叫Abstraction Layer


開始做新的Supplier


把舊的Supplier換掉,大功告成
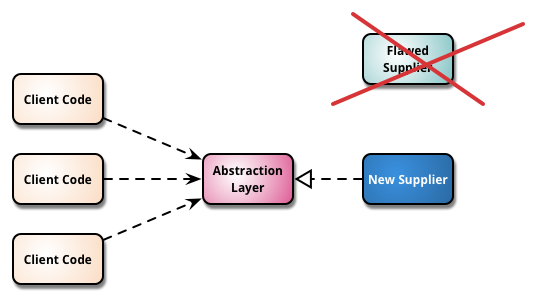

好處
- 只有一個小團隊會被影響
- 在修改中,trunk不會被Break,因為整個產品都是可以編譯可以跑的狀態
- 由於不會被Break,所以管理面可以滿足Schedule
- 避免Merge Hell
- 導入抽象層可以增加對架構的了解與優化Model,這件事本身就有好處
當然Branch By Abstraction不是萬靈丹,它只是一種Developer/架構師可以套用的實務作法,它用來取代架構師建議的Long Running Feature Branch,架構師應該爭取使用BBA而不是另開Branch。
什麼時候該Branch
真正的Branch應該只有在Release的時候,應該長的像這樣
<root>
trunk/
releases/
rel-1.0/
rel-1.1/
rel-1.2.x/
- 在Release前幾天才Branch
- 這個Branch當然是從trunk分支出來
- 然後作"Production harden"(為了產品化把bug修掉,集中測試,禁止別人亂改),Developer不能Commit到Release
- 只有被指派的人(在這裡是Release Engineer)才能Commit
- 讓CI證明trunk一直都保持良好的狀態
24-2009/5/2更新
- Mercurial,Git取代SVN變成主流
- 採用TBD,配合"Branch by Abstraction",與"little and often commits",與Agile Development搭配得很好。
Multi Branch VS trunk圖解
使用Multi Branch的示意圖

戰況報導:
- 紅色是無法正常執行產品所有功能的狀態
- 在任何分支之間都有可能有合併動作
- 某些Branch很短命,某些Branch很長命
- 某些Branch在開發時注意的是使用者介面下去的功能是否正常(應用程式開發Team)
- 某些Branch在開發時注重底層架構效能(引擎開發Team)
- 這就是混亂的代表
- 每個Branch都有可能Release
會遇到的問題:
- 一個獨立的Branch在經過幾周之後,有可能變成無法發布
- 研發團隊回報,他們整天在合併,解決合併相關的問題,沒辦法做正事
- 常會有Regressions,合併的時候總是會漏掉某些東西,然後就被業務部門X爆
- 標記Branch與處理標記讓人想換工作
如果用Trunk model就會長的像這樣
戰況報導:
- 所有人的開發都在Trunk上(這張有隱含一些細節,接下來的圖會說明)
- Release都在Release Branch上做
- 只有Bug fix會進Release,然後合併回Trunk(能先進Trunk再進Release更好)
- 幾乎每一天產品都是可以執行的,而且可以Deploy
- 可以滿足這句: "be ready to go live within a day's notice, and have a high level of confidence",隨時要出都可以
細節部分:

灰色部分可以是Developer本機下載的Code,或是小型的Private Repository,其他團隊看不到,沒有機會也禁止修改。
2014年1月31日 星期五
筆記:TBD是三小?---What is Trunk Based Development?
讀過了Perforce官方的mainline model的文件,又看到Google與Facebook都使用TBD,以及我自己在開發上遇到的問題,讓我想看看TBD到底如何可以幫助我們解決這些工程上的問題,看起來作者非常反對feature branch,而我自己親身經歷的感受也的確,要開feature branch,除非能做到Perforce官方推薦的經營方式,不然不只Merge會有災難,開發時也是災難連連。以人性角度來說,假設我做componentA,如果有10個feature branch都有componentA,那每個branch有問題我都要去看,我修了一個componentA的問題,由於每個branch分支出去的時間點不同,其它branch有的可能有,有的可能沒有這個問題,那我怎辦,只能等著人家來報問題,那我的時間很多都花在解這些Branch的問題上。如果採用的是TBD的概念,我只要保證trunk沒問題就可以了。或許在code撰寫方式上需要花很多工,但是我只需一次工,也可以將焦點集中在一個地方。對於我這種普通人,這是比較人性化的工作方式。
甚麼是TBD


- 一個軟體開發的分支模型,也被稱作mainline
- 同一個產品開發的所有人員共享一個Repository,有一個trunk,單一Developer或是Developer團隊可以有自己的private branch,所有修改最後都會回到主幹
- 只有在Release時才會有官方的分支,一般Developer不能對Release Branch作動作,只有Release Engineer可以更動Release Branch,當Release Branch完成它的任務,就會被砍掉。
- Google與Facebook都採用這種分支模型
有需要Release才Branch
- Release之後的branch,就不會有大的更動,只有Release Engineer會進行將挑選Commit合併到Release Branch的動作
- 多一個Release Engineer的帽子
- Bug先在trunk修好,之後把Commit合併到Release Branch,而不是在Release Branch修好再整合到trunk,這樣可以把修改Release Branch的人限制在最小程度。
Developer的責任
- 每個Developer都要保證Build會成功
- Google與Facebook在新進員工訓練下很多工夫在這上面。一開始沒生產沒關係,但是不要讓公司產品Build不出來!
- Rollback/revert是最後不得已的策略
- 複雜產品或是大公司都會有一堆Pre-Commit認證。
- Developer應該養成習慣,證明Commit是沒問題的:
- Commit之前把Code更新到最新
- 以最新的狀態將整個產品重Build一次
- 確認更改到的功能無誤(當然關聯的功能也要確認一下)
- Commit,總算搞定,休息一下
當某個功能花太長時間才能開發完
- 使用Branch By Abstraction (2013重提)
- 避免Branch到處開,最後整合不回來
什麼不是TBD
TBD Quick cheklist
- Developer幾乎只commit到單一trunk
- Release Engineer創建Release Branches, 幾乎只把Commit整合到Release Branch
- 用「幾乎只」來形容是因為如果bug無法在trunk重現(有可能是相關的code已被改變),那Developer就要在Release Branch上修正,然後把Commit整合到trunk。
如果應用Release Branch的概念,請記住:
- TBD代表Developer不能Commit到Release Branch
- TBD代表你將會刪除不再使用的Release Branches,不會做任何整合回trunk的動作
Developer需要Commit到多個Branch
- 當然不是TBD
- 如果想要Branch,請使用Branch by Abstraction
- 老鳥總是會說有Special Case需要Branch
- 重點就是合併的複雜度,10個Branch,每個人都在那邊Commit來Commit去,有些相關,有些不相關,有些Commit到2個Branch,有些Commit到1個Branch。這我超有感,我們團隊面臨到的狀況正是如此。
- To Branch or Not to Branch?這是已經被爭論許久的問題。
- 作者說除了Release Branch之外,不應該有任何Branch在共用的Repository上,但是Developer或是Developer團隊可以有自己的Private Branch。
- 就算Feature需要花很長的時間做而且沒時間花在整合上,還是不應該Branch by Feature,應該使用Branch by Abstraction。我們團隊遇到大Feature就會開一個Branch,由於這種Featrue Branch沒人經營,Feature開發中後期,就會花很多時間在整合,而複雜度隨著Commit數量增加越來越複雜,最後只要提到要整合回mainline,每個人的態度都是把一切交給命運。
沒有在Branch上作持續整合
- 不是TBD
- 很多Open Source的Developer聲稱沒有持續整合也不會怎樣,作者建議有10個以上的Developer就應該要做持續整合。個人認為就算1個也應該做,誰敢說自己完全不會改壞自己的Code。
手動管理Component Dependency版號
- 對外來的Component,通常都是用外面已經Build好的穩定版本,版號是固定的,可以直接寫Build管理檔案內(例如makefile,Maven的pom.xml)
- 對於內部的Component,自己手動指定該Build所需的Component版號(Ex:1.1.2之類),很容易造成不知到哪個版本的產品該用哪個版本的Component,要嘛就是把Code拉近Product Dir裡面全部Compnent都Build新的,要嘛就是根據Perforce或SVN的Revision Number,或是用Jenkins產的Build Number。手動是複雜度的地獄。
範例:
Perforce或SVN的架構
trunk
releasecomponent1component2component3component4productAproductB
private


productA用到component1,component3
productB用到component2,component4
要Build productA,CI可以先build component1,component2,然後build productA,但因為可能component1不斷開發,已經到了reversion=1500,而productA不需要reversion=1234後續開發的功能,就可選擇從component1的reversion=1234抓code過來build。或是直接把compoent1的reversion=1234的code放到到productA底下,目錄架構就會變成
trunk
component1
component2
productA
component1
component2
在Perforce有Module這個概念可以應用,History也會留存。
CI不是從Root開始Build
- CI在Build所有的Component都應該重新開始Build,不可以有任何的快取,或是已經Build好的Component,因為這樣無法反應code的最新狀態。
用詞不當
Mainline意指其他事物
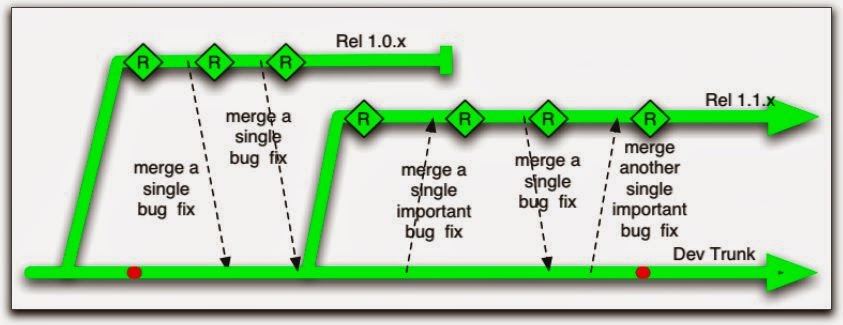
基本上Mainline就是指TBD,不過在1993年的ClearCase,它的mainline長的如下圖:
這是一個非常花時間的Branch Model,它的精神就是最後才整合,與TBD的早期整合正好相反。
上圖的劇本:
- mainline開發一段時間,Branch出1.1.x
- mainline繼續開發,1.1.x也繼續開發
- 接下來1.1.0要Release,即將合併回mainle,maineline因為要開發1.2.x,害怕1.1.0整合進來會很亂,所以先Branch出1.2。
- 1.1.x功能告一段落,1.1.0Release,此時合併回mainline,由於mainline的code已經不太相同,合併就是災難。
- 1.2繼續開發,mainline繼續處理混亂狀態
- 1.1.1Release,因為1.2需要有1.1的功能,所以又要合併回mainline,剛處理好混亂狀態的mainline要再處理一次混亂
- mainline處理完混亂,開始合併到1.2.x,因為兩個branch長得又不太一樣,所以又是災難
- 1.2處理完mainline下來的混亂之後,終於可以Release 1.2.0
可以看到,每次合併都是一場災難,而這個災難的次數還真不少。其實我們也是使用這個方式,由於有兩個以上的新版本同時開發,branch出去,branch執行有問題也不知道找誰修,要再回到mainline又是一堆工,雖然Branch by Abstraction不見得是萬靈丹,但作者提出的問題我已經有親身體會。
Feature Toggle
Martin Flower歸納出來的名詞,這個技巧是對一些已實作或是實作中,但還不想開放的功能,目前有些人以為這是與TBD一起用的,其實不然,這招早就存在,分為以下兩種
- Toggles at runtime,執行時期判斷旗標,看要不要開放此功能。
- Toggles at build time,建置時間判斷建置參數,看要不要把功能相關程式碼build進去。
不管如何,CI Server可以很好地對應這種需求
Branching is not the problem, merging is the problem
這就是TBD所想要解決的問題,Branch很方便,不是毒蛇猛獸,但是要如何管理好Branch,就是軟體工程的奧妙之處。
訂閱:
文章 (Atom)
-
 原文: http://paulhammant.com/2013/04/05/what-is-trunk-based-development/ 讀過了Perforce官方的mainline model的文件,又看到Google與Facebook都使用TBD,以及我自己在...
原文: http://paulhammant.com/2013/04/05/what-is-trunk-based-development/ 讀過了Perforce官方的mainline model的文件,又看到Google與Facebook都使用TBD,以及我自己在... -
最近有機會看RESTful API的設計,雖然自己沒有參與,但是也把握機會看了一遍。首先先從Http協定說起,Http協定不只用在傳輸Web的內容上,也有很多Client應用程式與Server溝通都使用Http協定,例如手機App,遊戲,甚至一些雲端的服務都是透過Http協定來提...
-
 來源: http://paulhammant.com/blog/branch_by_abstraction.html 接下來就看看Branch By Abstraction有多厲害,實際看下來,的確是一套很有用的方法,簡單來說,就是把整合的工分散到每日的開發中。但是要...
來源: http://paulhammant.com/blog/branch_by_abstraction.html 接下來就看看Branch By Abstraction有多厲害,實際看下來,的確是一套很有用的方法,簡單來說,就是把整合的工分散到每日的開發中。但是要...